sqoop - Sqooping Oracle Data simple steps - apache sqoop - sqoop tutorial - sqoop hadoop
How to Sqooping Oracle Data in Sqoop?
- These are some of the steps to get a quick example of sqooping Oracle Data into HDFS and Hive table which is done using the Oracle Developer VM and Hortonworks Sandbox.
Step 1:
- First, Download Hortonworks Sandbox and we need to import ova into VirtualBox
http://hortonworks.com/products/sandbox/
Click "Copy code" button to copy into clipboard - By wikitechy - sqoop tutorial - team
Step 2:
- First, Download Hortonworks Sandbox and we need to import ova into VirtualBox
- Then, Download Oracle Developer VM and this also has to be import ova into VirtualBox.
http://www.oracle.com/technetwork/database/enterprise-edition/databaseappdev-vm-161299.html
Click "Copy code" button to copy into clipboard - By wikitechy - sqoop tutorial - team
Step 3:
- After that, we need to set up the 2 VMs so they can communicate with each other.
- These are some of the diagrams which are given below to help. We need to basically set up the new Nat Network in Virtualbox under the Vitualbox Preference menu -> select network icon and add new Nat Network (display below - and called it Dens Network).
- Then, we go into the settings for both VM’s,
- Then, we go into network,
- We need to click on 2nd adapter and it is shown in the diagram which is given below.
VB Nat Network Diagram
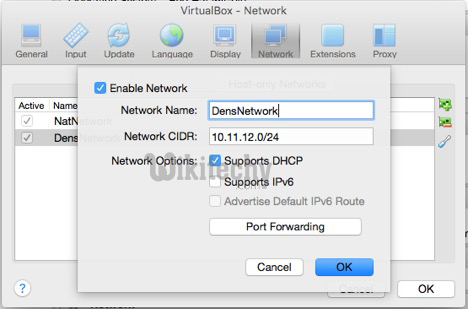
Learn sqoop - sqoop tutorial - Sqoop VB Nat Network - sqoop examples - sqoop programs
VB Settings - Sandbox
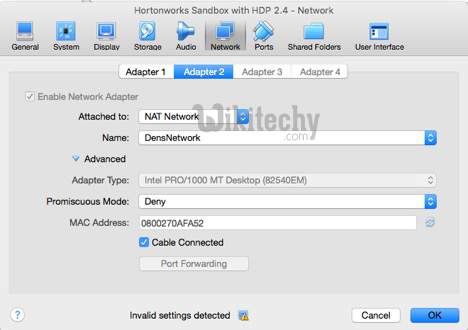
Learn sqoop - sqoop tutorial - Sqoop VB Nat Network - sqoop examples - sqoop programs
VB Setting - Oracle VM

Learn sqoop - sqoop tutorial - VB Settings Oracle VM - sqoop examples - sqoop programs
Step 4:
- We need to Fire up the VM’s, open a terminal session, and ssh into the sandbox
ssh -p 2222 root@sandbox.hortonworks.com or ssh -p 2222 root@127.0.0.1 - pw-hadoop
Click "Copy code" button to copy into clipboard - By wikitechy - sqoop tutorial - team
Step 5:
- We can read a little about Oracle CDB and PDB, it will help us with understanding the Jdbc connection.
http://docs.oracle.com/database/121/CNCPT/cdbovrvw.htm#CNCPT89236
Click "Copy code" button to copy into clipboard - By wikitechy - sqoop tutorial - team
Step 6:
- Sqoop will need the ojdbc6.jar in order to run the process correctly
Step 7:
- We need to Sqoop list table and Sqoop employees into HDFS(Hadoop Disturbed File System).
list system tables
Sqoop list-tables --connect jdbc:oracle:thin:system/oracle@10.11.12.5:1521:orcl12c
Click "Copy code" button to copy into clipboard - By wikitechy - sqoop tutorial - team
list Pdb tables
Sqoop list-tables -driver oracle.jdbc.driver.OracleDriver --connect jdbc:oracle:thin:system/oracle@10.11.12.5:1521/orcl --username system --password oracle
Click "Copy code" button to copy into clipboard - By wikitechy - sqoop tutorial - team
Import employee table
- hadoop fs -rm -R /user/hive/data/employees/
- sqoop import --connect jdbc:oracle:thin:system/oracle@10.11.12.5:1521/orcl --username system --password oracle --table HR.EMPLOYEES --target-dir /user/hive/data/employees
- hadoop fs -ls /user/hive/data/employees
- hadoop fs -cat /user/hive/data/employees/part-m-00000
Step 8:
Add and load a hive table by using beeline:
- Enter beeline on sandbox terminal window
- connect - !connect jdbc:hive2://sandbox.hortonworks.com:10000 sandbox pw or !connect jdbc:hive2://127.0.0.1:10000
- create database HR;
- USE HR;
- CREATE TABLE employees (employee_id int, first_name varchar(20), last_name varchar(25), email varchar(25), phone_number varchar(20), hire_date date, job_id varchar(10), salary int, commission_pct int, manager_id int, department_id int) row format delimited fields terminated by ',' lines terminated by '\n' stored as textfile;
- LOAD DATA INPATH '/user/hive/data/employees/' OVERWRITE INTO TABLE employees;
- Go ahead and query the table