sqoop - Sqoop with Oracle - apache sqoop - sqoop tutorial - sqoop hadoop
Sqoop with Oracle - Reference data in RDBMS
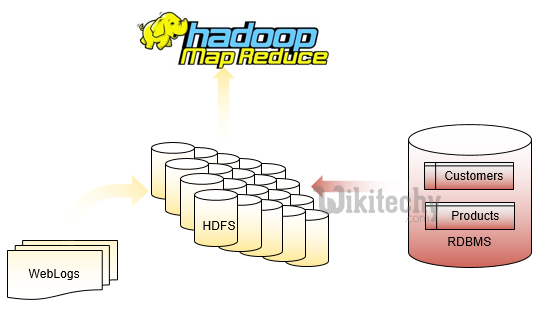
Sqoop with Oracle - Hadoop for off-line analytics
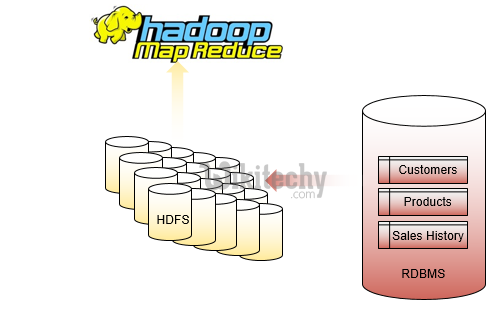
Sqoop with Oracle - Hadoop for RDBMS archive
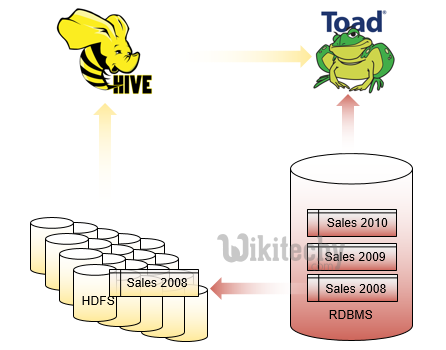
Sqoop with Oracle - MapReduce results to RDBMS
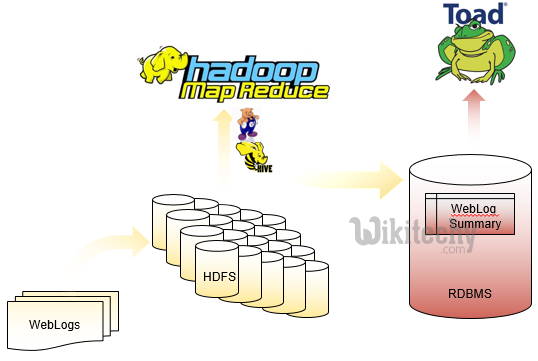
SQOOP Details
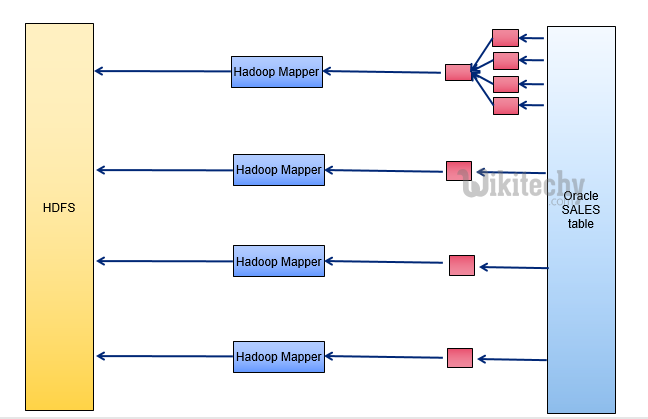
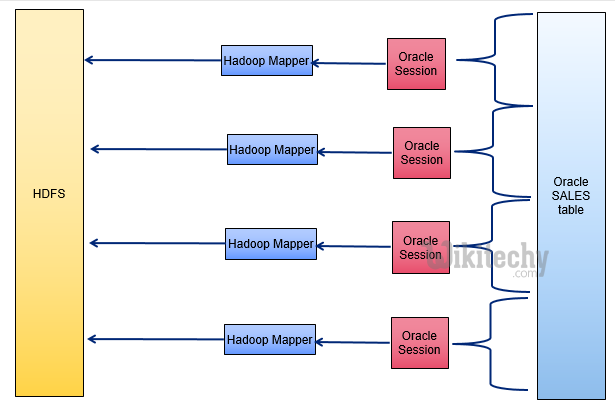
- Divide table into ranges using primary key max/min
- Create mappers for each range
- Mappers write to multiple HDFS nodes
- Creates text or sequence files
- Generates Java class for resulting HDFS file
- Generates Hive definition and auto-loads into HIVE
- Read files in HDFS directory via MapReduce
- Bulk parallel insert into database table
- Compatible with almost any JDBC enabled database
- Auto load into HIVE
- Hbase support
- Special handling for database LOBs
- Job management
- Cluster configuration (jar file distribution)
- WHERE clause support
- Open source, and included in Cloudera distributions
- Invoke mysqldump, mysqlimport for MySQL jobs
- Similar fast paths for PostgreSQL
- Extensibility architecture for 3rd parties (like Quest)
- Teradata, Netezza, etc.
Working with Oracle
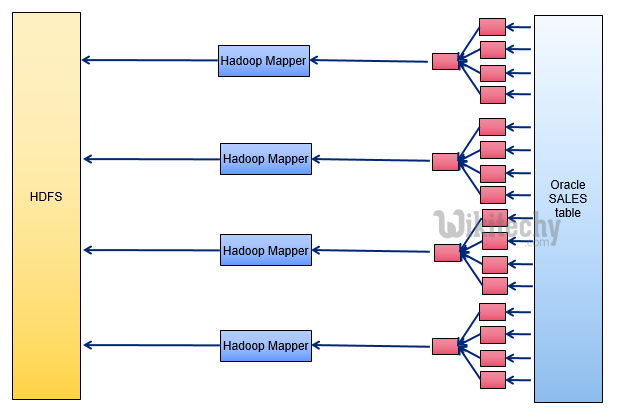
- vs. faster multi-block table scans
- Pollutes cache increasing IO for other users
- Limited help to SQOOP since rows are only read once
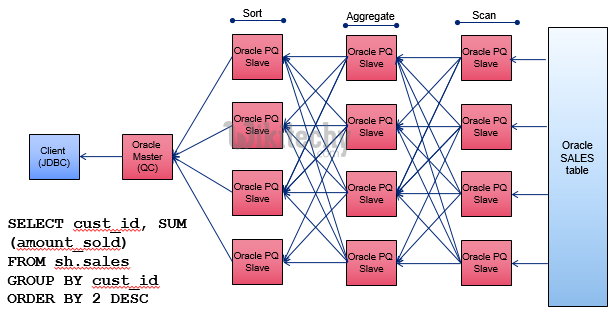
Oracle – parallelism :
Index range scans
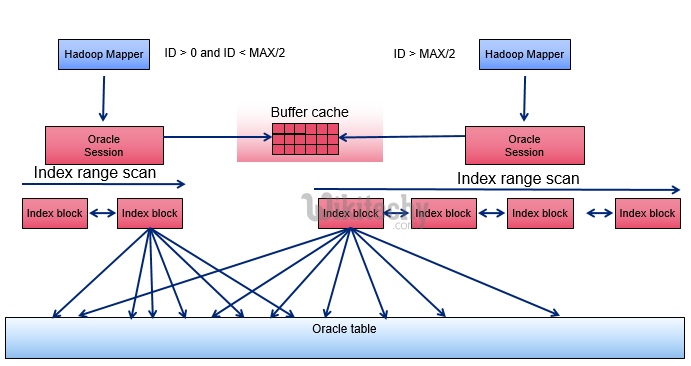
Oracle Ideal architecture
SQOOP/OraOop best practices
- Set inline-lob-limit
- Can’t rely on mapred.max.maps.per.node
- Leads to duplicate DB reads
- Keeps the mappers streaming to HDFS