sqoop - Sqoop vs Hive - apache sqoop - sqoop tutorial - sqoop hadoop
Sqoop related tags : sqoop import , sqoop interview questions , sqoop export , sqoop commands , sqoop user guide , sqoop documentation
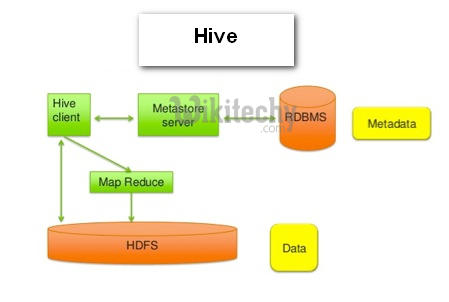
What is Hive?
- Apache Hive data warehouse software facilitates reading, writing, and managing large datasets which is done in distributed storage by using SQL.
Learn sqoop - sqoop tutorial - sqoop vs hive - sqoop examples - sqoop programs
Sqoop related tags : sqoop import , sqoop interview questions , sqoop export , sqoop commands , sqoop user guide , sqoop documentation
Difference between Sqoop and Hive:
| Sqoop | Hive |
|---|---|
| Sqoop is a tool which is used to transfer large amounts of data from Hadoop to the relational database servers and vice-versa i.e. from relational database servers to Hadoop |
Apache Hive is a data warehouse software that lets you read, write and manage huge volumes of datasets that is stored in a distributed environment using SQL. |
| Sqoop can be used to import the various types of data from Oracle, MySQL and such other databases. |
It is possible to project structure onto data that is in storage. Users can connect to Hive using a JDBC driver and a command line tool. |
| Sqoop allows to Export and Import the data from the data table based on the where clause. |
Hive does not provide fundamental features required for OLTP(Online Transaction Processing) and it is suitable for data warehouse applications in large data sets. |
| Sqoop needs a connector to connect the different relational databases. Almost all Database vendors make a JDBC connector available specific to that Database, Sqoop needs a JDBC driver of the database for interaction. |
Hive is suitable for data warehouse applications in large data sets. |
| Example: sqoop import –connect jdbc:mysql://db.one.com/corp –table INTELLIPAAT_EMP –where “start_date> ’2016-07-20’ ” |
Example: hive>SET hive.enforce.bucketing hive.enforce.bucketing=true |