sqoop - Sqoop vs Flume - apache sqoop - sqoop tutorial - sqoop hadoop
What is Flume?
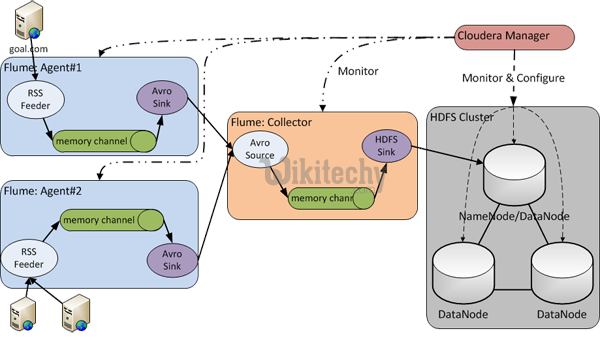
- Apache Flume is service designed for streaming logs into Hadoop environment and it is a distributed and reliable service for collecting and aggregating huge amounts of log data.
Learn sqoop - sqoop tutorial - Sqoop vs Flume - sqoop examples - sqoop programs
Difference between Sqoop and Flume:
| Sqoop | Flume |
|---|---|
| Sqoop is used for importing data from structured data sources such as RDBMS. |
Flume is used for moving bulk streaming data into HDFS. |
| Sqoop has a connector based architecture. Connectors know how to connect to the respective data source and fetch the data. | Flume has an agent based architecture. Here, code is written (which is called as 'agent') which takes care of fetching data. |
| HDFS is a destination for data import using Sqoop. | Data flows to HDFS through zero or more channels. |
| Sqoop data load is not event driven. | Flume data load can be driven by event. |
| In order to import data from structured data sources, one has to use Sqoop only, because its connectors know how to interact with structured data sources and fetch data from them. |
In order to load streaming data such as tweets generated on Twitter or log files of a web server, Flume should be used. Flume agents are built for fetching streaming data. |