sqoop - Sqoop Overview - apache sqoop - sqoop tutorial - sqoop hadoop
What is Sqoop Overview?
- Efficiently transfers bulk data between Apache Hadoop and structured datastores.
- Apache Sqoop efficiently transfers bulk data between Apache Hadoop and structured datastores such as relational databases.
- Sqoop helps offload certain tasks (such as ETL processing) from the EDW to Hadoop for efficient execution at a much lower cost.
- Sqoop can also be used to extract data from Hadoop and export it into external structured datastores.
- Sqoop works with relational databases such as Teradata, Netezza, Oracle, MySQL, Postgres, and HSQLDB
Why is Sqoop used?

- For Hadoop developers, the interesting work starts after data is loaded into HDFS.
- Developers play around the data in order to find the magical insights concealed in that Big Data.
- For this, the data residing in the relational database management systems need to be transferred to HDFS, play around the data and might need to transfer back to relational database management systems.
- In reality of Big Data world, Developers feel the transferring of data between relational database systems and HDFS is not that interesting, tedious but too seldom required.
- Developers can always write custom scripts to transfer data in and out of Hadoop, but Apache Sqoop provides an alternative.
- Sqoop automates most of the process, depends on the database to describe the schema of the data to be imported.
- Sqoop uses MapReduce framework to import and export the data, which provides parallel mechanism as well as fault tolerance.
- Sqoop makes developers life easy by providing command line interface.
- Developers just need to provide basic information like source, destination and database authentication details in the sqoop command. Sqoop takes care of remaining part.
Features
- Full Load
- Incremental Load
- Parallel import/export
- Import results of SQL query
- Compression
- Connectors for all major RDBMS Databases
- Kerberos Security Integration
- Load data directly into Hive/Hbase
- Support for Accumulo
- Sqoop is Robust, has great community support and contributions.
- Sqoop is widely used in most of the Big Data companies to transfer data between relational databases and Hadoop.
Where is Sqoop used?
- Relational database systems are widely used to interact with the traditional business applications.
- So, relational database systems has become one of the sources that generate Big Data.
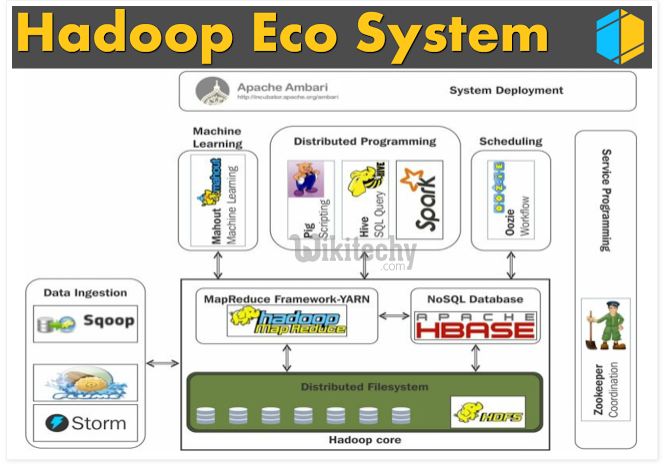
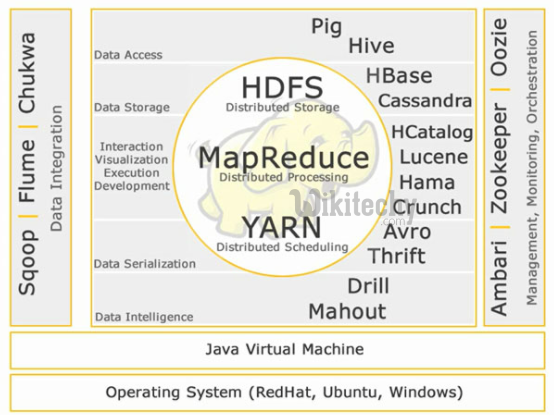
- As we are dealing with Big Data, Hadoop stores and processes the Big Data using different processing frameworks like MapReduce, Hive, HBase, Cassandra, Pig etc and storage frameworks like HDFS to achieve benefit of distributed computing and distributed storage.
- In order to store and analyze the Big Data from relational databases, Data need to be transferred between database systems and Hadoop Distributed File System (HDFS).
- Here, Sqoop comes into picture. Sqoop acts like a intermediate layer between Hadoop and relational database systems.
- You can import data and export data between relational database systems and Hadoop and its eco-systems directly using sqoop.
Learn sqoop - sqoop tutorial - process of sqoop - sqoop examples - sqoop programs
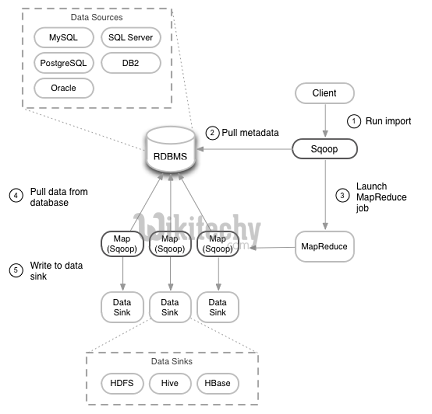
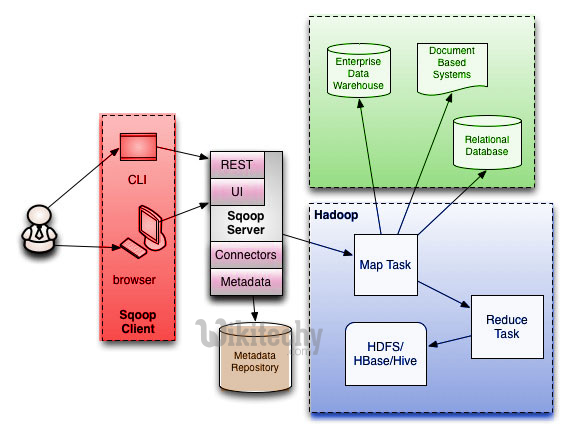
Sqoop Architecture
- Sqoop provides command line interface to the end users.
- Sqoop can also be accessed using Java APIs.
- Sqoop command submitted by the end user is parsed by Sqoop and launches Hadoop Map only job to import or export data because Reduce phase is required only when aggregations are needed.
- Sqoop just imports and exports the data; it does not do any aggregations.
Motivation:
- Hadoop MapReduce is a powerful tool; its flexibility in parsing unstructured or semi-structured data means that there is a lot of potential for creative applications.
- But your analyses are only as useful as the data which they process. In many organizations, large volumes of useful information are locked away in disparate databases across the enterprise.
- HDFS, Hadoop’s distributed file system represents a great place to bring this data together, but actually doing so is a cumbersome task.
- Consider the task of processing access logs and analysing user behavior on your web site.
- Users may present your site with a cookie that identifies who they are. You can log the cookies in conjunction with the pages they visit.
- This lets you coordinate users with their actions. But actually matching their behavior against their profiles or their previously recorded history requires that you look up information in a database.
- If several MapReduce programs needed to do similar joins, the database server would experience very high load, in addition to a large number of concurrent connections, while MapReduce programs were running, possibly causing performance of your interactive web site to suffer.
- The solution: periodically dump the contents of the users database and the action history database to HDFS, and let your MapReduce programs join against the data stored there.
- Going one step further, you could take the in-HDFS copy of the users database and import it into Hive, allowing you to perform ad-hoc SQL queries against the entire database without working on the production database.
- Sqoop makes all of the above possible with a single command-line.
Advantages of Sqoop
- Allows the transfer of data with a variety of structured data stores like Postgres, Oracle, Teradata, and so on.
- Since the data is transferred and stored in Hadoop, Sqoop allows us to offload certain processing done in the ETL (Extract, Load and Transform) process into low-cost, fast, and effective Hadoop processes.
- Sqoop can execute the data transfer in parallel, so execution can be quick and more cost effective.
- Helps to integrate with sequential data from the mainframe. This helps not only to limit the usage of the mainframe, but also reduces the high cost in executing certain jobs using mainframe hardware.
Sqoop related tags : sqoop import , sqoop interview questions , sqoop export , sqoop commands , sqoop user guide , sqoop documentation
Disadvantages of Sqoop
- It uses a JDBC connection to connect with RDBMS based data stores, and this can be inefficient and less performant.
- For performing analysis, it executes various map-reduce jobs and, at times, this can be time consuming when there are lot of joins if the data is in a denormalized fashion.
- Being used for bulk transfer of data, it could put undue pressure on the source data store, and this is not ideal if these stores are heavily used by the main business application.