sqoop - Sqoop Merge - apache sqoop - sqoop tutorial - sqoop hadoop
What is sqoop merge?
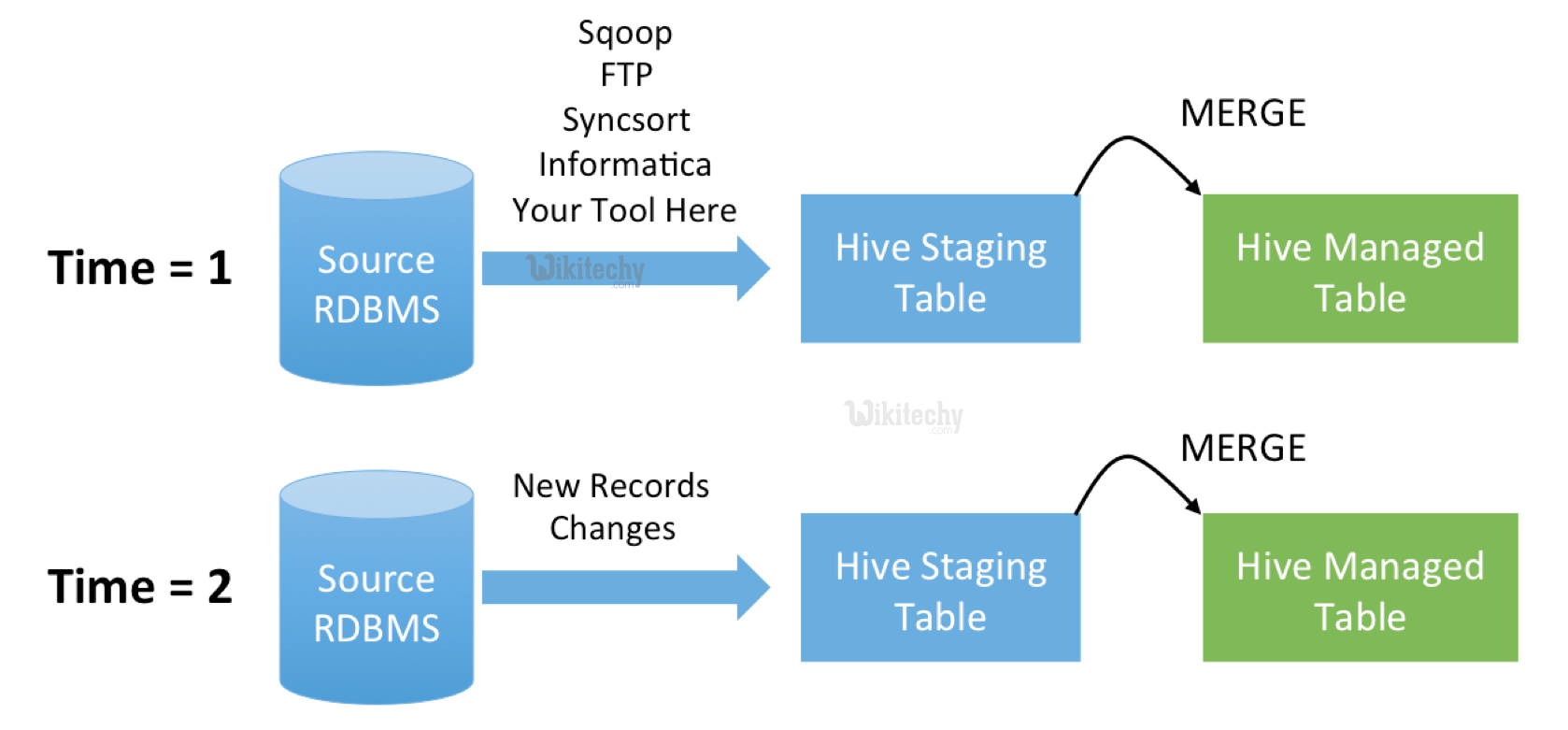
- The Sqoop merge tool allows you to combine two datasets where entries in one dataset should overwrite entries of an older dataset.
- Apache Sqoop is a tool that is designed to efficiently transfer large amounts of data between Apache Hadoop and structured data stores such as relational databases. ...
- After the merge operation completes, you could import the data back into a Hive or HBase data store.
Learn sqoop - sqoop tutorial - rdbms source - sqoop examples - sqoop programs
Syntax
$ sqoop merge (generic-args) (merge-args)
$ sqoop-merge (generic-args) (merge-args)
Click "Copy code" button to copy into clipboard - By wikitechy - sqoop tutorial - team
- Although the Hadoop generic arguments must preceed any merge arguments, the job arguments can be entered in any order with respect to one another.
Merge options:
| Argument | Description |
|---|---|
| --class-name <class > | Specify the name of the record-specific class to use during the merge job. |
| --jar-file <file> | Specify the name of the jar to load the record class from. |
| --merge-key <col> | Specify the name of a column to use as the merge key. |
| --new-data <path> |
Specify the path of the newer dataset. |
| --onto <path> | Specify the path of the older dataset. |
| --target-dir <path> | Specify the target path for the output of the merge job. |
- The merge tool runs a MapReduce job that takes two directories as input: a newer dataset, and an older one. These are specified with --new-data and -onto respectively. The output of the MapReduce job will be placed in the directory in HDFS specified by --target-dir.
- When merging the datasets, it is assumed that there is a unique primary key value in each record. The column for the primary key is specified with --merge-key. Multiple rows in the same dataset should not have the same primary key, or else data loss may occur.
- To parse the dataset and extract the key column, the auto-generated class from a previous import must be used. You should specify the class name and jar file with --class-name and --jar-file. If this is not availab,e you can recreate the class using the codegen tool.
- The merge tool is typically run after an incremental import with the date-last-modified mode (sqoop import -incremental lastmodified …).
- Supposing two incremental imports were performed, where some older data is in an HDFS directory named older and newer data is in an HDFS directory named newer, these could be merged like so:
$ sqoop merge --new-data newer --onto older --target-dir merged \
--jar-file datatypes.jar --class-name Foo --merge-key id
Click "Copy code" button to copy into clipboard - By wikitechy - sqoop tutorial - team
- This would run a MapReduce job where the value in the id column of each row is used to join rows; rows in the newer dataset will be used in preference to rows in the older dataset.
- This can be used with both SequenceFile-, Avro- and text-based incremental imports. The file types of the newer and older datasets must be the same.
Example
- An incremental import run in last-modified mode will generate multiple datasets in HDFS where successively newer data appears in each dataset.
- The merge tool will "flatten" two datasets into one, taking the newest available records for each primary key.
Lets Create a TEST Database in MySQL
create database test;
use test;
Click "Copy code" button to copy into clipboard - By wikitechy - sqoop tutorial - team
Lets Create an Employee Table
- Create table emp(empid int not null primary key, empname VARCHAR(20), age int, salary int, city VARCHAR(20),cr_date date);
Describe table
mysql> describe emp;
+---------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+-------------+------+-----+---------+-------+
| empid | int(11) | NO | PRI | NULL | |
| empname | varchar(20) | YES | | NULL | |
| age | int(11) | YES | | NULL | |
| salary | int(11) | YES | | NULL | |
| city | varchar(20) | YES | | NULL | |
| cr_date | date | YES | | NULL | |
+---------+-------------+------+-----+---------+-------+
Click "Copy code" button to copy into clipboard - By wikitechy - sqoop tutorial - team
Load the Employee table
LOAD DATA LOCAL INFILE '/Users/gangadharkadam/Downloads/empdata.csv'
INTO TABLE emp
FIELDS TERMINATED BY ','
ENCLOSED BY '/'
LINES TERMINATED BY '\n'
IGNORE 1 LINES
(empid, empname, age, salary, city, @var1)
Click "Copy code" button to copy into clipboard - By wikitechy - sqoop tutorial - team
Set
cr_date = STR_TO_DATE(@var1, '%m/%d/%Y');
Click "Copy code" button to copy into clipboard - By wikitechy - sqoop tutorial - team
- # Import the the emp table to hdfs using below command
sqoop import --connect jdbc:mysql://localhost/TEST --table emp --username hive -password hive --target-dir /sqoop/empdata/
Click "Copy code" button to copy into clipboard - By wikitechy - sqoop tutorial - team
- # Update the few records in the TEST.emp table as below
update emp set cr_date='2016-02-28' where empname like "A%";
Click "Copy code" button to copy into clipboard - By wikitechy - sqoop tutorial - team
- # Now Merge these updated record with the HDFS file using --merge-key option
- #merge tool will "flatten" two datasets into one
sqoop import --connect jdbc:mysql://localhost/test --table emp \
--username hive -password hive --incremental lastmodified --merge-key empid --check-column cr_date \
--target-dir /sqoop/empdata/