apache hive - How to Stores Data in Hive - hive tutorial - hadoop hive - hadoop hive - hiveql
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
What is Data Store?
- Data Store is a repository for persistently storing and managing collections of data which include not just repositories like databases, but also simpler store types such as simple files, emails etc.
- A database is a series of bytes that is managed by a database management system (DBMS).
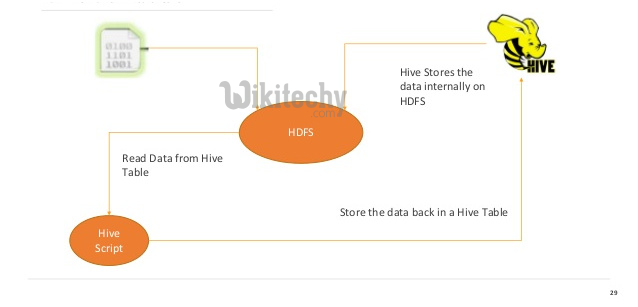
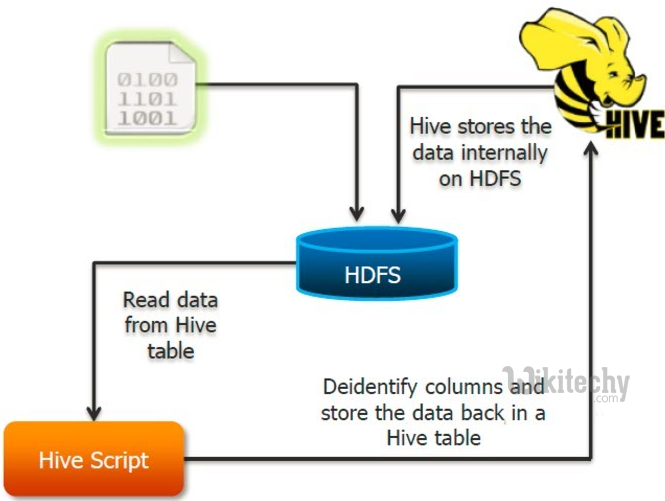
Where does hive store data?
- Hive and Pig work on the principle of schema on read.
- The data is loaded into HDFS and stored in files within directories.
- The schema is applied during Hive queries and Pig data flow executions.
- The schema or metadata is read from the metastore via the HCatalog API.
apache hive - learn hive - hive tutorial - big data introduction - hive example
What is meant by HDFS?
- The Hadoop Distributed File System (HDFS) is a sub-project of the Apache Hadoop project.
- This Apache Software Foundation project is designed to provide a fault-tolerant file system designed to run on commodity hardware.
- It is the primary storage system used by Hadoop applications.
- HDFS is a distributed file system that provides high-performance access to data across Hadoop clusters.
How to efficiently store data in hive/ Store and retrieve compressed data in hive?
- Hive is a data warehousing tool built on top of hadoop.
- The data corresponding to hive tables are stored as delimited files in hdfs.
- Since it is used for data warehousing, the data for production system hive tables would definitely be at least in terms of hundreds of gigs.
- Now naturally the question arises, how efficiently we can store this data, definitely it has to be compressed.
- Now let’s look into these, it is fairly simple if you know hive. Before you use hive you need to enable a few parameters for dealing with compressed tables.
- It is the same compression enablers when you play around with map reduce along with a few of hive parameters.
hive.exec.compress.output=true
mapred.output.compress=true
mapred.output.compression.codec=com.hadoop.compression.lzo.LzopCodec
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
- Here, we have used LZO as my compression in hdfs, hence using the LzopCodec. Beyond setting this you don’t need to do anything else, use the hive QLs normally as you do with uncompressed data.
- We have tried out the same successfully with Dynamic Partitions, Buckets etc, It works like any normal hive operations.
- The input data for me from conventional sources were normal text, this raw data was loaded into a staging table.
- From the staging table with some hive QL the cleansed data was loaded into actual hive tables.
- The staging table gets flushed every time the data is loaded into target hive table.
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
Hive Data Models
Table Data Models
- Page views table name: pvs
- HDFS directory
------------------/wh/pvs
Partitions Data Models
- Partition columns: ds, ctry
- HDFS subdirectory for ds = 20090801, ctry = US
- HDFS subdirectory for ds = 20090801, ctry = CA
------------------/wh/pvs/ds=20090801/ctry=US
------------------/wh/pvs/ds=20090801/ctry=CA
Buckets Data Models
- Bucket column: user into 32 buckets
- HDFS file for user hash 0
------------------/wh/pvs/ds=20090801/ctry=US/part-00000 - HDFS file for user hash bucket 20
------------------/wh/pvs/ds=20090801/ctry=US/part-00020
External Tables Data Models
CREATE EXTERNAL TABLE pvs(userid int, pageid int, ds string, ctry string) PARTITIONED ON (ds string, ctry string) STORED AS textfile LOCATION ‘/path/to/existing/table’
ALTER TABLE pvs ADD PARTITION (ds=‘20090801’, ctry=‘US’) LOCATION ‘/path/to/existing/partition’
Load CSV file into Hive
learn hive - hive tutorial - apache hive - load csv file into hive - hive examples