apache hive - Hive - Language Capabilities - hive tutorial - hadoop hive - hadoop hive - hiveql
- Hive is a data warehousing infrastructure built on top of apache Hadoop.
- Hadoop provides massive scale-out and fault-tolerance capabilities for data storage and processing (using the MapReduce programming paradigm) on commodity hardware.
- Hive enables easy data summarization, ad-hoc querying and analysis of large volumes of data.
- It is best used for batch jobs over large sets of immutable data (like web logs).
- It provides a simple query language called Hive QL, which is based on SQL and which enables users familiar with SQL to easily perform ad-hoc querying, summarization and data analysis.
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
Hive - Data Flow Architecture at Facebook :
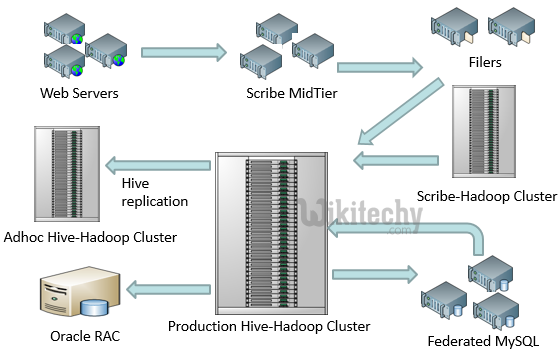
learn hive - hive tutorial - apache hive - data flow architecture - hive examples
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
Hive Query Language capabilities:
- Hive query language provides the basic SQL like operations. These operations work on tables or partitions.
- Ability to create and manage tables and partitions (create, drop and alter).
- Ability to support various Relational, Arithmetic and Logical Operators.
- Ability to do various joins between two tables.
- Ability to evaluate functions like aggregations on multiple “group by” columns in a table.
- Ability to store the results of a query into another table.
- Ability to download the contents of a table to a local directory.
- Ability to create an external table that points to a specified location within HDFS
- Ability to store the results of a query in an HDFS directory.
- Ability to plug in custom scripts using the language of choice for custom map/reduce jobs.
Hive & Hadoop Usage @ Facebook :
- 5800 cores, Raw Storage capacity of 8.7 PetaBytes
- 12 TB per node
- Two level network topology
- 1 Gbit/sec from node to rack switch
- 4 Gbit/sec to top level rack switch
- 12 TB of compressed new data added per day
- 135TB of compressed data scanned per day
- 7500+ Hive jobs per day
- 80K compute hours per day
- New engineers go though a Hive training session
- ~200 people/month run jobs on Hadoop/Hive
- Analysts (non-engineers) use Hadoop through Hive
- 95% of jobs are Hive Jobs
Types of Applications:
- Eg: Daily/Weekly aggregations of impression/click counts
- Measures of user engagement
- Microstrategy reports
- Eg: how many group admins broken down by state/country
- Ad Optimization
- Eg: User Engagement as a function of user attributes
Major Components of Hive and its interaction with Hadoop:
- Hive provides external interfaces like command line (CLI) and web UI, and application programming interfaces (API) like JDBC and ODBC
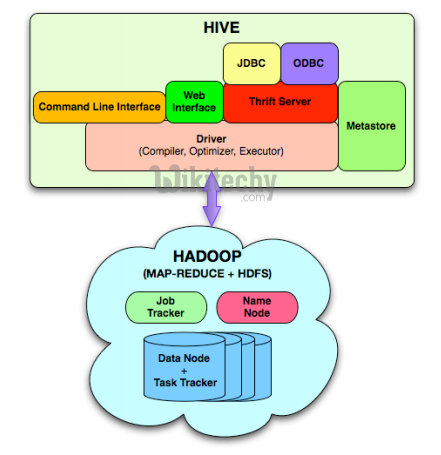
Learn Hive Tutorials - Hive Architecture - Hive Example
- The Hive Thrift Server exposes a very simple client API to execute HiveQL statements. Thrift is a framework for cross-language services, where a server written in one language (like Java) can also support clients in other languages.
- The Metastore is the system catalog. All other components of Hive interact with the Metastore.
- The Driver manages the life cycle of a HiveQL statement during compilation, optimization and execution.
- The Compiler is invoked by the driver upon receiving a HiveQL statement. The compiler translates this statement into a plan which consists of a DAG of map/reduce jobs.
- The driver submits the individual map/reduce jobs from the DAG to the Execution Engine in a topological order. Hive currently uses Hadoop as its execution engine.
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
ORCFile – Columnar Storage for Hive :
- Only needed columns are read
- Blocks of data can be skipped using indexes and predicate pushdown
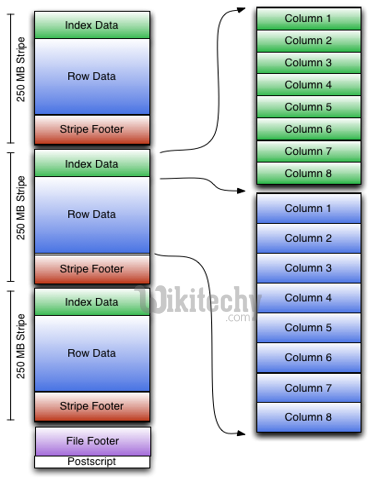
learn hive - hive tutorial - apache hive - data from hbase to hive - orc file - columnar storage hive - hive examples
- Each partition is associated with a folder in HDFS
- All partitions have an entry in the Hive Catalog
- The Hive optimizer will parse the query for filter conditions and skip unneeded partitions
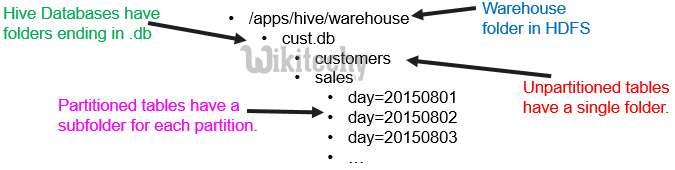
learn hive - hive tutorial - apache hive - data from hbase to hive - hive partitioning folder structure - hive examples
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
Hive ORCFile – Predicate pushdown :
- ORC ( and other storage formats ) support predicate pushdown
- Query filters are pushed down into the storage handler
- Blocks of data can be skipped without reading them from HDFS based on ORC index
SELECT SUM (PROFIT) FROM SALES WHERE DAY = 03

learn hive - hive tutorial - apache hive - data from hbase to hive - hive predicate push down - hive examples
Hive - Partitioning vs. Predicate Pushdown :
Partitioning works at split generation, no need to start containers
Predicate pushdown is applied during file reads
Impact on Optimizer and HCatalog for large number of partitions
Thousands of partitions will result in performance problems
Container are allocated even though they can run very quickly
No overhead in Optimizer/Catalog
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
Hive - Partitioning and Predicate Pushdown :
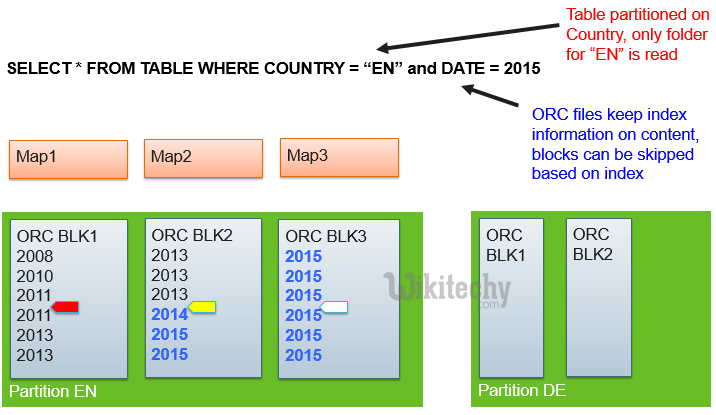
learn hive - hive tutorial - apache hive - data from hbase to hive - hive partitioning push down - hive examples
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
Hive - Loading Data with Dynamic Partitioning :

learn hive - hive tutorial - apache hive - data from hbase to hive - hive dynamic partitioning - hive examples
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
Hive - More Real-World Use Cases :
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
Hive - Interfaces to Front End UI technology :
Main form of integration with php based Web UI