apache hive - HiveQL Select Group By - Hive jdbc program - hive tutorial - hadoop hive - hadoop hive - hiveql
What is Select-Group By in HiveQL ?
- Here, We explains the details of GROUP BY clause in a SELECT statement.
- The GROUP BY clause is used to group all the records in a result set using a particular collection column.
- It is used to query a group of records.
- The GROUP BY clause groups records into summary rows.GROUP BY returns one records for each group.
- It typically also involves aggregates: COUNT, MAX, SUM, AVG, etc. And it can group by one or more columns.
learn hive - hive tutorial - apache hive - process of hiveql select group by - hive examples
learn hive - hive tutorial - apache hive - hive group by map reduce program - hive examples
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
The GROUP BY clause’s important characteristics are:
- The GROUP BY clause comes after the WHERE clause and before the ORDER BY clause.
- Grouping columns can be column names or derived columns.
- Every nonaggregate column in the SELECT clause must appear in the GROUP BY clause. This statement is illegal because pub_id isn’t in the GROUP BY clause:
SELECT type, pub_id , COUNT(*)
FROM titles
GROUP BY type; --IllegalClicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team

learn hive - hive tutorial - apache hive - hive group by - hive examples
- Because the GROUP BY can return only one row for each value of type, there’s no way to return multiple values of pub_id that are associated with any particular value of type.
- If the SELECT clause contains a complex nonaggregate expression (more than just a simple column name), the GROUP BY expression must match the SELECT expression exactly.
- Specify multiple grouping columns in the GROUP BY clause to nest groups. Data is summarized at the last specified group.
learn hive - hive tutorial - hive sql datatypes - hive programs - hive examples
Basic Syntax :
The syntax of GROUP BY clause is as follows:
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[HAVING having_condition]
[ORDER BY col_list]]
[LIMIT number];
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
Example:
- Let us take an example of SELECT…GROUP BY clause.
- Assume employee table as given below, with Id, Name, Salary, Designation, and Dept fields.
- Generate a query to retrieve the number of employees in each department.
| ID | Name | Salary | Designation | Dept |
|---|---|---|---|---|
| 1201 | Aarthi | 45000 | Technical manager | TP |
| 1202 | Boomi | 45000 | Proofreader | PR |
| 1203 | Dharsanya | 40000 | Technical writer | TP |
| 1204 | Harikka | 40000 | Hr Admin | HR |
| 1205 | Mirunalini | 30000 | Op Admin | Admin |
- The following query retrieves the employee details using the above scenario.
hive> SELECT Dept,count(*) FROM employee GROUP BY DEPT;
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
On successful execution of the query, you get to see the following response:
| Dept | Count(*) |
|---|---|
| Admin | 1 |
| PR | 2 |
| TP | 3 |
JDBC Program:
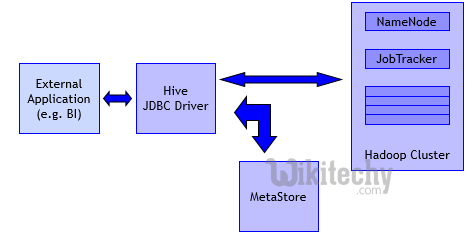
learn hive - hive tutorial - apache hive - hive jdbc driver - hive examples
Given below is the JDBC program to apply the Group By clause for the given example.
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class WikitechyGroupBy {
private static String driverName = "org.apache.hadoop.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
// Register driver and create driver instance
Class.forName(driverName);
// get connection
Connection con = DriverManager.
getConnection("jdbc:hive://localhost:10000/userdb", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statement
Resultset res = stmt.executeQuery(“SELECT Dept,count(*) ” + “FROM employee GROUP BY DEPT; ”);
System.out.println(" Dept \t count(*)");
while (res.next()) {
System.out.println(res.getString(1) + " " + res.getInt(2));
}
con.close();
}
}
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
Save the program in a file named WikitechyGroupBy.java. Use the following commands to compile and execute this program.
$ javac WikitechyGroupBy.java
$ java WikitechyGroupBy
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy hive tutorial team
Output:
| Dept | Count(*) |
|---|---|
| Admin | 1 |
| PR | 2 |
| TP | 3 |
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
Hive QL – Group By - Optimizations :
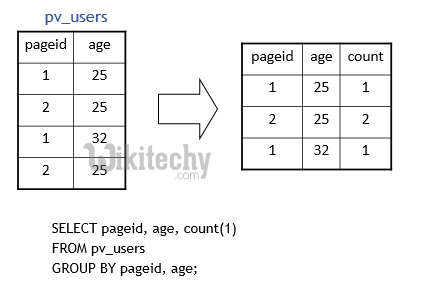
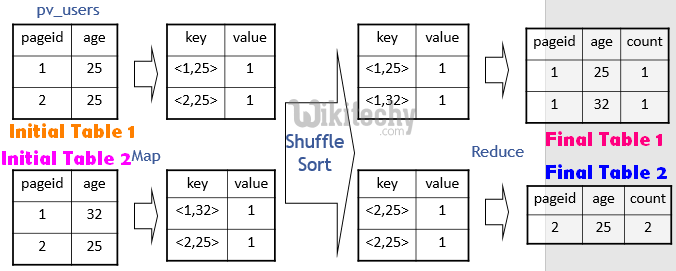
FROM pv_users
GROUP BY pageid, age;
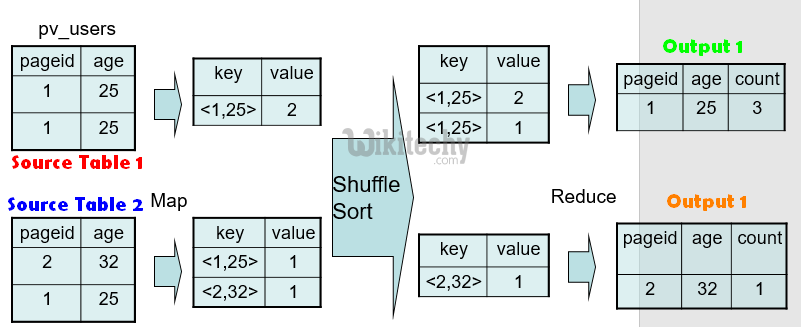
learn hive - hive tutorial - apache hive - hive group by mapreduce - hive examples
- Map side partial aggregations
- Hash-based aggregates
- Serialized key/values in hash tables
- 90% speed improvement on Query SELECT count(1) FROM t;
- Load balancing for data skew
Parameters for Group by Optimization :
- hive.map.aggr = true
- hive.groupby.skewindata = false
- hive.groupby.mapaggr.checkinterval = 100000
- hive.map.aggr.hash.percentmemory = 0.5
- hive.map.aggr.hash.min.reduction = 0.5
apache hive related article tags - hive tutorial - hadoop hive - hadoop hive - hiveql - hive hadoop - learnhive - hive sql
Group By with distinct - big data map reduce - Optimizations :

learn hive - hive tutorial - apache hive - hive group by with distinct map reduce program - hive examples
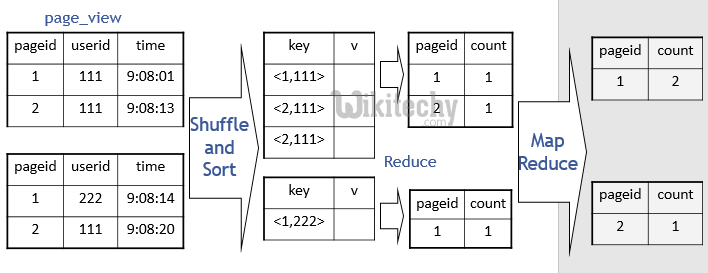
learn hive - hive tutorial - apache hive - hive group by with distinct map reduce program - hive examples