Basic Elasticsearch Concepts - elasticsearch - elasticsearch tutorial - elastic search
Elasticsearch Basic Concepts
- Elasticsearch is a real-time distributed and open source full-text search and analytics engine.
- It is accessible from RESTful web service interface and uses schema less JSON (JavaScript Object Notation) documents to store data.
- It is built on Java programming language, which enables Elasticsearch to run on different platforms.
- It enables users to explore very large amount of data at very high speed.
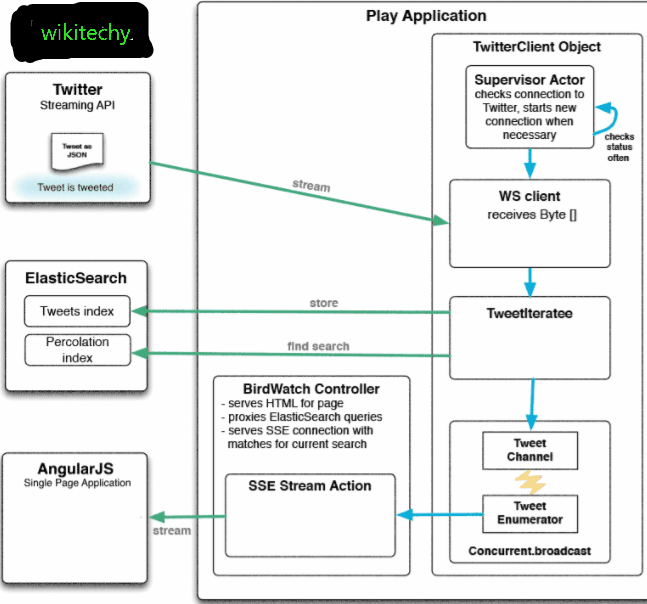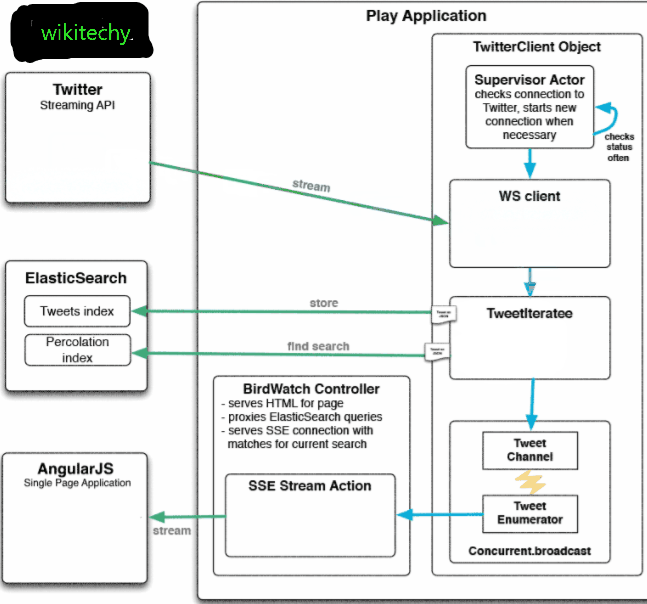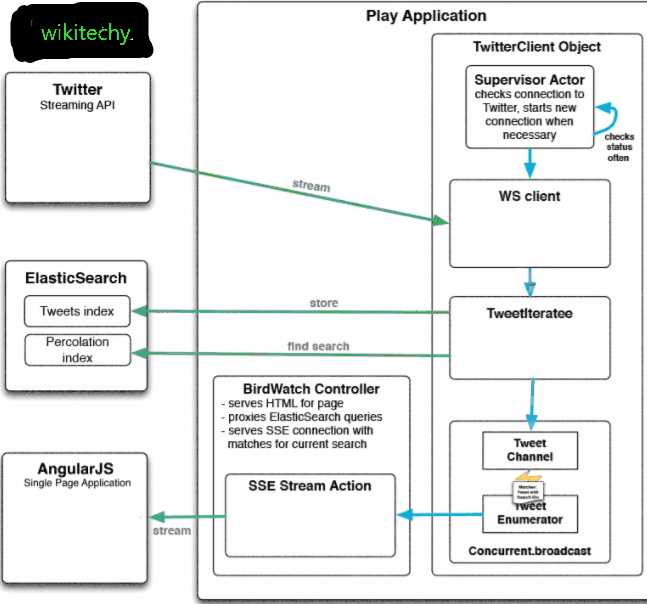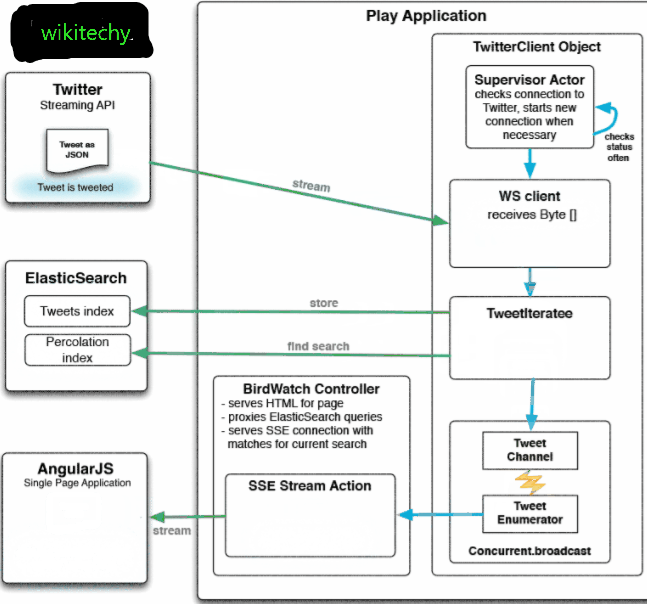
learn elasticsearch tutorials - twitter and working functionality Example
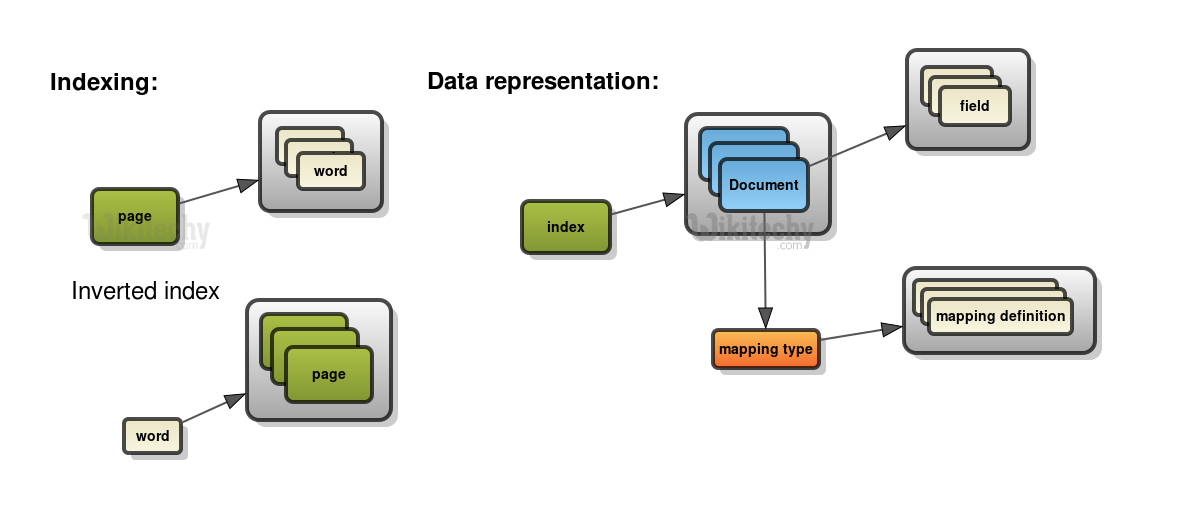
Indexing:
- Elasticsearch is a real-time distributed and open source full-text search and analytics engine.
- It is accessible from RESTful web service interface and uses schema less JSON (JavaScript Object Notation) documents to store data.
- It is built on Java programming language, which enables Elasticsearch to run on different platforms.
- It enables users to explore very large amount of data at very high speed.
How Elasticsearch represents data?
- In Elasticsearch, a Document is the unit of search and index.
- An index consists of one or more Documents, and a Document consists of one or more Fields.
- In database terminology, a Document corresponds to a table row, and a Field corresponds to a table column.
Schema:
- Unlike Solr, Elasticsearch is schema-free. Well, kinda.
- Whilst you are not required to specify a schema before indexing documents, it is necessary to add mapping declarations if you require anything but the most basic fields and operations.
This is no different from specifying a schema!
- The schema declares:
- what fields there are
- which field should be used as the unique/primary key
- which fields are required
- how to index and search each field
- In Elasticsearch, an index may store documents of different "mapping types".
- You can associate multiple mapping definitions for each mapping type. A mapping type is a way of separating the documents in an index into logical groups.
- To create a mapping, you will need the Put Mapping API, or you can add multiple mappings when you create an index.
Query DSL:
- The Query DSL is Elasticsearch's way of making Lucene's query syntax accessible to users, allowing complex queries to be composed using a JSON syntax.
- Like Lucene, there are basic queries such as term or prefix queries and also compound queries like the bool query.
The main structure of a query is roughly:
curl -X POST "http://localhost:9200/blog/_search?pretty=true" -d ‘
{"from": 0,
"size": 10,
"query" : QUERY_JSON,
FILTER_JSON,
FACET_JSON,
SORT_JSON
}’
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy - elasticsearch - elasticsearch tutorial - elastic - elastic search - elasticsearch docker team
Lucene:
- Elasticsearch is powered by Lucene, a powerful open-source full-text search library, under the hood.
- The relationship between Elasticsearch and Lucene, is like that of the relationship between a car and its engine.
- For the purpose of this introduction, we haven't differentiated between the two, just as to most people, the distinction between a car and its engine is not terribly important when learning how to drive a car.
- However, to a mechanic, the distinction is a very important one. Similarly, when we dive deeper under the bonnet of Elasticsearch, we'll explore the distinctions between Lucene and ElasticSearch in detail.
Near Realtime (NRT):
- Elasticsearch is a near real time search platform.
- What this means is there is a slight latency (normally one second) from the time you index a document until the time it becomes searchable.
Cluster:
- A cluster is a collection of one or more nodes (servers) that together holds your entire data and provides federated indexing and search capabilities across all nodes.
- A cluster is identified by a unique name which by default is "elasticsearch".
- This name is important because a node can only be part of a cluster if the node is set up to join the cluster by its name.
- Make sure that you don’t reuse the same cluster names in different environments, otherwise you might end up with nodes joining the wrong cluster.
- For instance, you could use logging-dev, logging-stage, and logging-prod for the development, staging, and production clusters.
Note: It is valid and perfectly fine to have a cluster with only a single node in it. Furthermore, you may also have multiple independent clusters each with its own unique cluster name.
elasticsearch - elasticsearch tutorial - elastic search - elasticsearch sort - elasticsearch list indexes - elasticsearch node
Node:
- A node is a single server that is part of your cluster, stores your data, and participates in the cluster’s indexing and search capabilities.
- Just like a cluster, a node is identified by a name which by default is a random Universally Unique IDentifier (UUID) that is assigned to the node at startup.
- You can define any node name you want if you do not want the default.
- This name is important for administration purposes where you want to identify which servers in your network correspond to which nodes in your Elasticsearch cluster.
- A node can be configured to join a specific cluster by the cluster name.
- By default, each node is set up to join a cluster named elasticsearch which means that if you start up a number of nodes on your network and—assuming they can discover each other—they will all automatically form and join a single cluster named elasticsearch.
- In a single cluster, you can have as many nodes as you want.
- Furthermore, if there are no other Elasticsearch nodes currently running on your network, starting a single node will by default form a new single-node cluster named elasticsearch.
learn elasticsearch tutorials - index Example
Index:
- An index is a collection of documents that have somewhat similar characteristics.
- For example, you can have an index for customer data, another index for a product catalog, and yet another index for order data.
- An index is identified by a name (that must be all lowercase) and this name is used to refer to the index when performing indexing, search, update, and delete operations against the documents in it.
- In a single cluster, you can define as many indexes as you want.
Type:
- Within an index, you can define one or more types.
- A type is a logical category/partition of your index whose semantics is completely up to you.
- In general, a type is defined for documents that have a set of common fields.
- For example, let’s assume you run a blogging platform and store all your data in a single index.
- In this index, you may define a type for user data, another type for blog data, and yet another type for comments data.
Document:
- A document is a basic unit of information that can be indexed.
- For example, you can have a document for a single customer, another document for a single product, and yet another for a single order.
- This document is expressed in JSON (JavaScript Object Notation) which is a ubiquitous internet data interchange format.
- Within an index/type, you can store as many documents as you want.
- Note that although a document physically resides in an index, a document actually must be indexed/assigned to a type inside an index.
Shards & Replicas:
- An index can potentially store a large amount of data that can exceed the hardware limits of a single node.
- For example, a single index of a billion documents taking up 1TB of disk space may not fit on the disk of a single node or may be too slow to serve search requests from a single node alone.
- To solve this problem, Elasticsearch provides the ability to subdivide your index into multiple pieces called shards.
- When you create an index, you can simply define the number of shards that you want.
- Each shard is in itself a fully-functional and independent "index" that can be hosted on any node in the cluster.
- Sharding is important for two primary reasons:
- It allows you to horizontally split/scale your content volume
- It allows you to distribute and parallelize operations across shards (potentially on multiple nodes) thus increasing performance/throughput
- The mechanics of how a shard is distributed and also how its documents are aggregated back into search requests are completely managed by Elasticsearch and is transparent to you as the user.
- In a network/cloud environment where failures can be expected anytime, it is very useful and highly recommended to have a failover mechanism in case a shard/node somehow goes offline or disappears for whatever reason. To this end, Elasticsearch allows you to make one or more copies of your index’s shards into what are called replica shards, or replicas for short.
- Replication is important for two primary reasons:
- It provides high availability in case a shard/node fails. For this reason, it is important to note that a replica shard is never allocated on the same node as the original/primary shard that it was copied from.
- It allows you to scale out your search volume/throughput since searches can be executed on all replicas in parallel.
- To summarize, each index can be split into multiple shards. An index can also be replicated zero (meaning no replicas) or more times. Once replicated, each index will have primary shards (the original shards that were replicated from) and replica shards (the copies of the primary shards). The number of shards and replicas can be defined per index at the time the index is created. After the index is created, you may change the number of replicas dynamically anytime but you cannot change the number of shards after-the-fact.
- By default, each index in Elasticsearch is allocated 5 primary shards and 1 replicate which means that if you have at least two nodes in your cluster, your index will have 5 primary shards and another 5 replica shards (1 complete replica) for a total of 10 shards per index.