Elasticsearch Analyzer - elasticsearch - elasticsearch tutorial - elastic search
Elasticsearch Analyzer
- Analysis is the process of converting text, like the body of any email, into tokens or terms which are added to the inverted index for searching.
- Analysis is performed by an analyzer which can be either a built-in analyzer or a custom analyzer defined per index.
learn elasticsearch tutorials - elasticsearch-compiler-intepretation analyzer Example
Request Body:
{
"settings": {
"analysis": {
"analyzer": {
"index_analyzer": {
"tokenizer": "standard", "filter": [
"standard", "my_delimiter", "lowercase", "stop",
"asciifolding", "porter_stem"
]
},
"search_analyzer": {
"tokenizer": "standard", "filter": [
"standard", "lowercase", "stop", "asciifolding", "porter_stem"
]
}
},
"filter": {
"my_delimiter": {
"type": "word_delimiter",
"generate_word_parts": true,
"catenate_words": true,
"catenate_numbers": true,
"catenate_all": true,
"split_on_case_change": true,
"preserve_original": true,
"split_on_numerics": true,
"stem_english_possessive": true
}
}
}
}
}
Clicking "Copy Code" button will copy the code into the clipboard - memory. Please paste(Ctrl+V) it in your destination. The code will get pasted. Happy coding from Wikitechy - elasticsearch - elasticsearch tutorial - elastic - elastic search - elasticsearch docker team
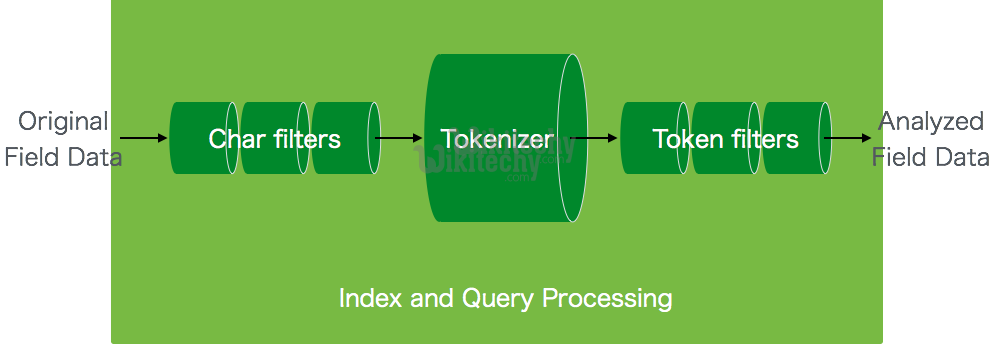
Analyzers:
- An analyzer consists of a tokenizer and optional token filters.
- These analyzers are registered in analysis module with logical names, which can be referenced either in mapping definitions or in some APIs.
- There are a number of default analyzers as follows
| Sr.No | Analyzer & Description |
|---|---|
| 1 | Standard analyzer (standard) stopwords and max_token_length setting can be set for this analyzer. By default, stopwords list is empty and max_token_length is 255. |
| 2 |
Simple analyzer (simple) This analyzer is composed of lowercase tokenizer. |
| 3 |
Whitespace analyzer (whitespace) This analyzer is composed of whitespace tokenizer. |
| 4 |
Stop analyzer (stop) stopwords and stopwords_path can be configured. By default stopwords initialized to English stop words and stopwords_path contains path to a text file with stop words. |
| 5 |
Keyword analyzer (keyword) This analyzer tokenizes an entire stream as a single token. It can be used for zip code. |
| 6 |
Pattern analyzer (pattern) This analyzer mainly deals with regular expressions. Settings like lowercase, pattern, flags, stopwords can be set in this analyzer. |
| 7 |
Language analyzer This analyzer deals with languages like hindi, arabic, ducth etc. |
| 8 |
Snowball analyzer (snowball) This analyzer uses the standard tokenizer, with standard filter, lowercase filter, stop filter, and snowball filter. |
| 9 |
Custom analyzer (custom) This analyzer is used to create customized analyzer with a tokenizer with optional token filters and char filters. Settings like tokenizer, filter, char_filter and position_increment_gap can be configured in this analyzer. |
Tokenizers:
- Tokenizers are used for generating tokens from a text in Elastic search.
- Text can be broken down into tokens by taking whitespace or other punctuations into account.
- Elastic search has plenty of built-in tokenizers, which can be used in custom analyzer.
learn elasticsearch tutorials - elasticsearch tokenizer analysisExample
| Sr.No | Tokenizer & Description |
|---|---|
| 1 | Standard tokenizer (standard) This is built on grammar based tokenizer and max_token_length can be configured for this tokenizer. |
| 2 | Edge NGram tokenizer (edgeNGram) Settings like min_gram, max_gram, token_chars can be set for this tokenizer. |
| 3 | Keyword tokenizer (keyword) This generates entire input as an output and buffer_size can be set for this. |
| 4 | Letter tokenizer (letter) This captures the whole word until a non-letter is encountered. |
| 5 | Lowercase tokenizer (lowercase) This works the same as the letter tokenizer, but after creating tokens, it changes them to lower case. |
| 6 | NGram Tokenizer (nGram) Settings like min_gram (default value is 1), max_gram (default value is 2) and token_chars can be set for this tokenizer. |
| 7 | Whitespace tokenizer (whitespace) This divides text on the basis of whitespaces. |
| 8 | Pattern tokenizer (pattern) This uses regular expressions as a token separator. Pattern, flags and group settings can be set for this tokenizer. |
| 9 | UAX Email URL Tokenizer (uax_url_email) This works same lie standard tokenizer but it treats email and URL as single token. |
| 10 | Path hierarchy tokenizer (path_hierarchy) This tokenizer generated all the possible paths present in the input directory path. Settings available for this tokenizer are delimiter (defaults to /), replacement, buffer_size (defaults to 1024), reverse (defaults to false) and skip (defaults to 0). |
| 11 | Classic tokenizer (classic) This works on the basis of grammar based tokens. max_token_length can be set for this tokenizer. |
| 12 | Thai tokenizer (thai) This tokenizer is used for Thai language and uses built-in Thai segmentation algorithm. |
Token Filters:
- Token filters receive input from tokenizers and then these filters can modify, delete or add text in that input.
- Elasticsearch offers plenty of built-in token filters. Most of them have already been explained in previous sections.
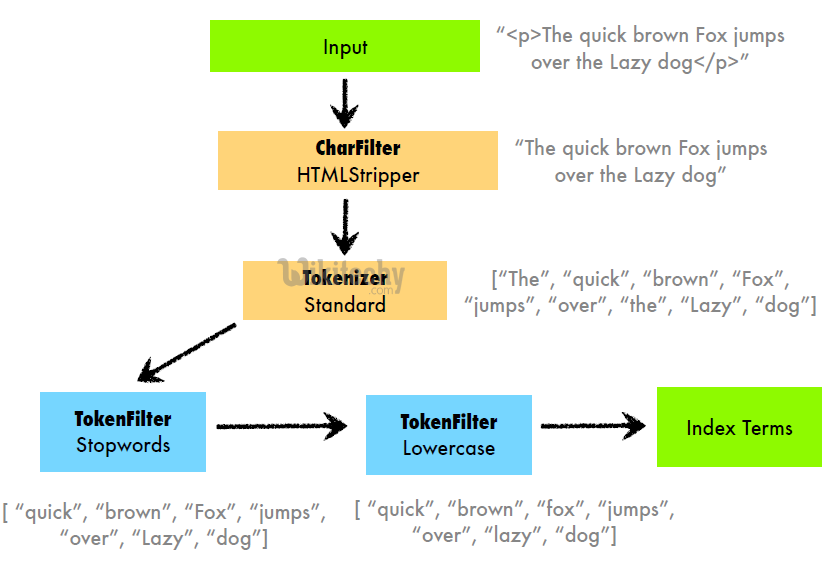
Character Filters:
- These filters process the text before tokenizers.
- Character filters look for special characters or html tags or specified pattern and then either delete then or change them to appropriate words like ‘&’ to and, delete html markup tags.
- Here is an example of analyzer with synonym specified in synonym.txt
{
"settings":{
"index":{
"analysis":{
"analyzer":{
"synonym":{
"tokenizer":"whitespace", "filter":["synonym"]
}
},
"filter":{
"synonym":{
"type":"synonym", "synonyms_path":"synonym.txt", "ignore_case":"true"
}
}
}
}
}
}